
評価尺度の信頼性と妥当性については第6回「観察研究はこう教えている―ランダム化比較試験が使えない時は」で簡単に触れていますが、統計学は後回しにしていたので今回扱います。一般的な統計学のテキストではこの事項については扱っていないことが多いですが、看護研究においてはQOLなど目に見えないものを測定する必要がありますので、1回かけてしっかりと講義しています(図1)。

例として用いるのは終末期がん患者の包括的なQOL尺度として私たちが作成したCoQoLo(Comprehensive Quality of Life Outcome Inventory)1)という尺度とがん患者の家族のQOL尺度であるCQOLC(Caregiver Quality of Life Index-Cancer)2)という尺度です。CQOLCは海外で作成された尺度で、私の教室の学生が卒業研究で日本語版の信頼性・妥当性の検討を行いました。信頼性と妥当性の検討に用いる統計学的手法は理論的に難しいものが多く、学部のレベルを超えているので、この講義では実際の例をいろいろ見せてイメージをつかんでもらうことを重視しています。本稿では実際の例についてはほとんど割愛しています。
評価尺度の信頼性
評価尺度の信頼性と妥当性とでは、まず信頼性から教えています。信頼性のほうが簡単だからです。私は信頼性=再現性と教えています。その中に、評価者間信頼性(評価者間再現性)と評価者内信頼性(評価者内再現性)があります(図2)。

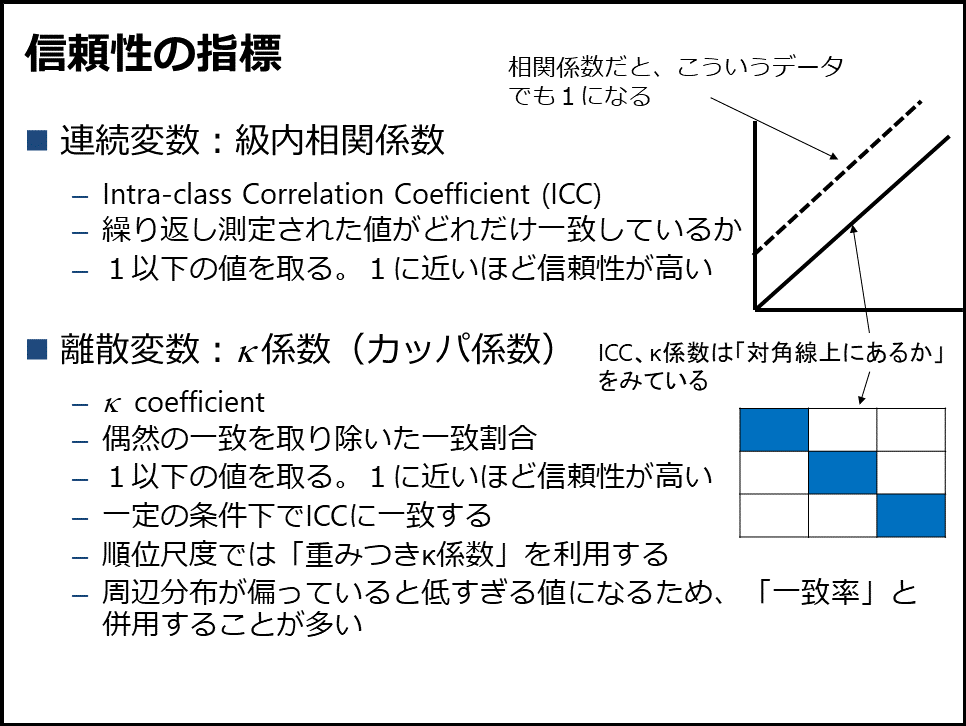
評価尺度の信頼性としては級内相関係数とκ係数について解説しています。指標の説明を簡単にしたあとに、信頼性の強さの指標としてLandis & Kochの基準について話しています。後述しますが、Cronbachのα係数は信頼性ではなく妥当性の指標として教えています(図3)。

評価尺度の妥当性
妥当性に関しては、内容的妥当性、構成概念妥当性、基準関連妥当性等に分けて話しています。
内容妥当性・表面妥当性
最初は内容的妥当性・表面的妥当性(見た目でもっともらしいか)ですが、Cognitive Interview(認知インタビュー)については第7回「量的研究の評価方法はこう教えている」で話しているので、ここでは簡単にしか触れていません(図4)。「統計学的な検討を行うことは稀である」と書いていますが、CVI(Content Validity Index)を使うことも多いので、CVIについては話したほうがいいかもしれません。

構成概念妥当性
次は構成概念妥当性(考えている概念を構成しているか)です。構成概念妥当性の評価は難しいです。なぜなら「本当に見たいもの」は通常よくわからないからです。たとえば「QOLは何か」「それは何から構成されているのか」と言われても、「本当のことはよくわからない」というのが実情です。それがはっきりしているなら、それは基準関連妥当性とよぶことができます。ですから、構成概念妥当性は通常「いくつかの方法の合わせ技」で「まあ、こういうデータが出ていれば、それなりに正しいといえるのでは」という程度の評価を行うことになります。
因子妥当性
構成概念妥当性に関しては、まず因子妥当性を説明します。因子分析の説明をしますが、これは5教科のテストで理系・文系にデータが分かれるという仮想データを用いて説明しています。確証的因子分析についても簡単に例を挙げて説明しています(図5)。

内的整合性
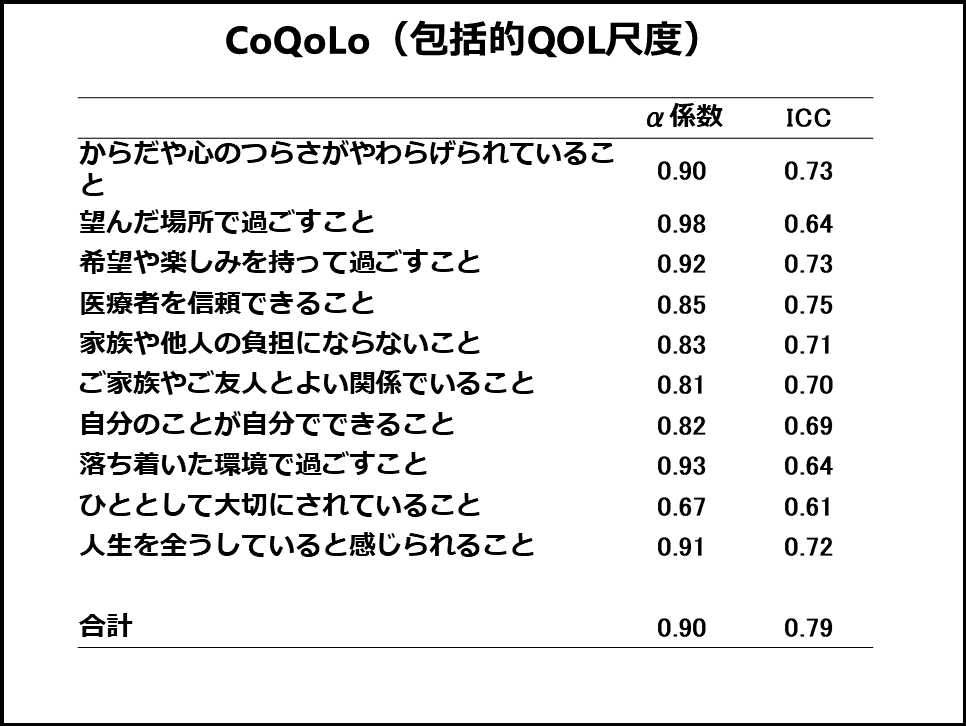
次は内的整合性(内的一貫性)です。私はCronbachのα係数は「尺度の各項目の相関係数の平均を取ったようなもの」として、内的整合性の基準として説明しています。その尺度(ドメイン)の項目が似たようなものであるかの指標です。Cronbachのα係数を信頼性の指標として使うことがあり、私も過去にはそのように論文を書いたことがあります。しかし、Cronbachのα係数を級内相関係数に近似するためにはかなり厳しい仮定が必要ですし、次のスライドに挙げたCoQoLoの例のようにCronbachのα係数が高くても級内相関係数(ICC)が高くない例を何度も経験したので、現在はCronbachのα係数をもって信頼性の指標とすることは勧めていません(CoQoLoはまだマシなほうで、もっと級内相関係数[ICC]が低くなった経験があります)(図6)。Cronbachのα係数が高ければ信頼性が高いことが「期待される」くらいでしょうか。やはり再現性に関しては面倒でも再テストが必須だと考えています。

併存妥当性
次は併存妥当性(同時的妥当性)です。これは似たような尺度と相関をとることによって、「だいたいこのようなことを測定している」ということを示すものです。これは高すぎるのも問題で、高すぎるということは、その外的基準として用いた尺度そのものを見ているだけなのではないかということになるからです。ちょうどよい相関というのがいくつ程度かわかりませんが、相関がありそうなところでそれなりの相関があり、相関がなさそうなところで相関が出ないというなんだか煮え切らない基準で判断することになります。後者は弁別妥当性ともいわれます(図7)。

基準関連妥当性
最後は基準関連妥当性です。基準関連妥当性はGold Standard(至適基準)とよばれる外的基準と関連があることです。基準関連妥当性の検討で重要なことはGold Standard―いわゆる「本当のこと」がわかっていないといけないことです。たまに、同時的妥当性と基準関連妥当性を混同している論文を見ることがあります。基準関連妥当性のなかでも、将来的な予測にかかわるものを予測妥当性として教えています。私の専門である緩和ケアの領域では予後予測研究などでよく使われています。既知集団妥当性も基準関連妥当性の中で教えていますが、健常者と患者を分けるような明らかな基準があるものは基準関連妥当性でもよいと思いますが、次のスライドに例示したようなPerformance Status(PS)とQOL尺度のようなものはどちらかといえば構成概念妥当性だと思います(図8)。

ここまで教えて、最後に感度(反応性:Responsiveness)と実施可能性について話し、報告ガイドラインであるCOSMINチェックリストの紹介をしてこの回は終わりです。

おわりに
ちなみに私は多くの緩和ケアに関する評価尺度の作成にかかわって来ました。おそらく30は超えるのではないかと思います。私が緩和ケアの研究を始めた頃は、「緩和ケアは定量的に測定できない」と言われました。そして、測定する尺度もなかったのです。私は緩和ケアの質評価ということを専門にしていますが、質を評価するためだけでなく、緩和ケアの研究を推進するためには測定道具を作ることから始めないといけなかったのです。
私は評価尺度の作成が上手なほうだと思います。それは上記のような経験があるからですが、評価尺度の作成を成功させるコツは「調査を2回すること」だと思います。1回目のDevelopment Phaseでは再調査はしなくてもよいですし、サンプル数もあまり多くなくてよいので、1回の横断調査で各項目の実際の分布や因子分析の結果などをみて、想定したとおりになっているかを調べます。たまに因子構造が想定と大きく異なることなどがありますし、複数ドメインを想定していたのに1因子になってしまうこともあります。1因子になってしまったら、方針を転換して1因子構造として作り直したほうがいいかもしれません。私も初学者の頃はドメインが思うように分かれると気持ちがよかったのですが、ドメインとして分かれても固有値をみると1因子ということも少なくありませんし、ドメインが多い尺度というのはあとで扱いが面倒になることもしばしばです。因子だけでなく各項目の表現や分布なども1回データを取ってみると、ああすればよかった、などと気づくことも多いです。そして、尺度をある程度洗練させたあとに、Validation Phaseの本当の信頼性・妥当性調査を行います。今度は再テストも行います。このように1回目の調査であたりをつけて洗練させることによって、信頼性・妥当性が保証された尺度を作成することができます。
1)Miyashita M et al:Development and validation of the Comprehensive Quality of Life Outcome (CoQoLo) inventory for patients with advanced cancer。 BMJ Support Palliat Care 9(1):75-83,2019
2)安藤早紀ほか:Caregiver Quality of Life Index - Cancer(CQOLC)日本語版の信頼性・妥当性の検証.Palliat Care Res 8(2):286-292,2013




