
医療統計学の講義もあと2回です。今回はいままでの一連の講義で扱うことができなかった3つのトピック、生存時間解析、診断・検査の統計学、症例数設計について扱います。
生存時間解析
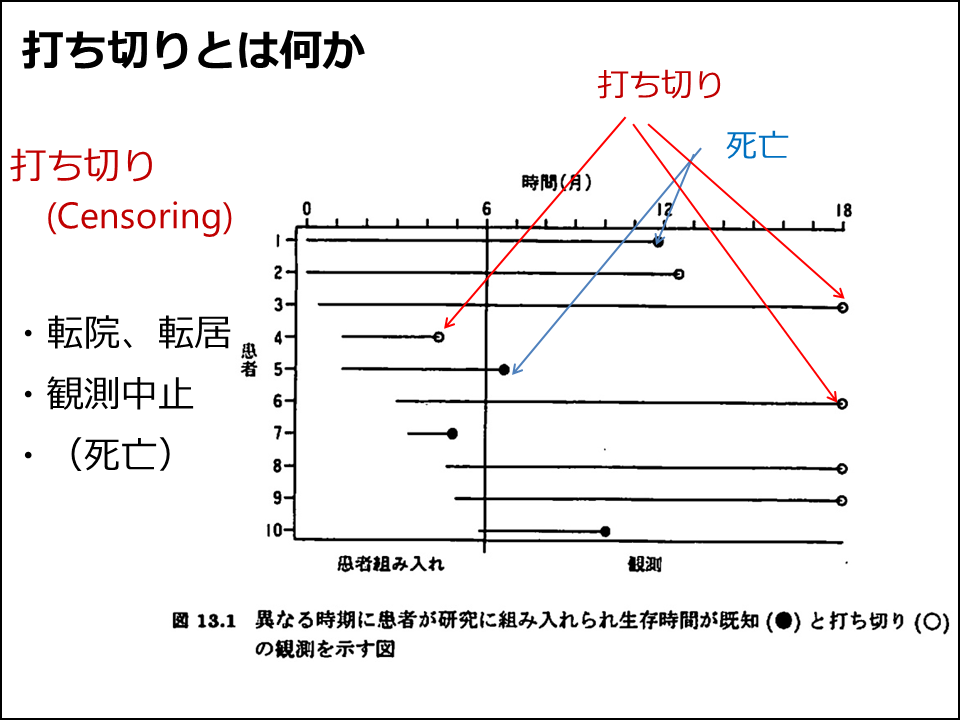
生存時間解析とは「時間」に関する分析方法ではありません。「打ち切りがあるデータ」に対する分析です。まずは最初にこの点を強調します。入院期間や死亡・疾病の発症までの「時間」に関する解析であっても、打ち切りがなくすべての生存期間が測定できていれば、t検定やWilcoxonの順位和検定などの連続データの解析方法を使用することができます。ただし、コホート研究をはじめとして追跡を伴う研究では打ち切りが生じることが多いので、そのような場合は生存期間解析という特殊な方法を用います。まずは打ち切りとは何かを示したうえで(図1)、生存期間の表示方法については打ち切りの有無にかかわらずカプラン・マイヤー法で生存確率を推定するために、それについても教えています(図2)。

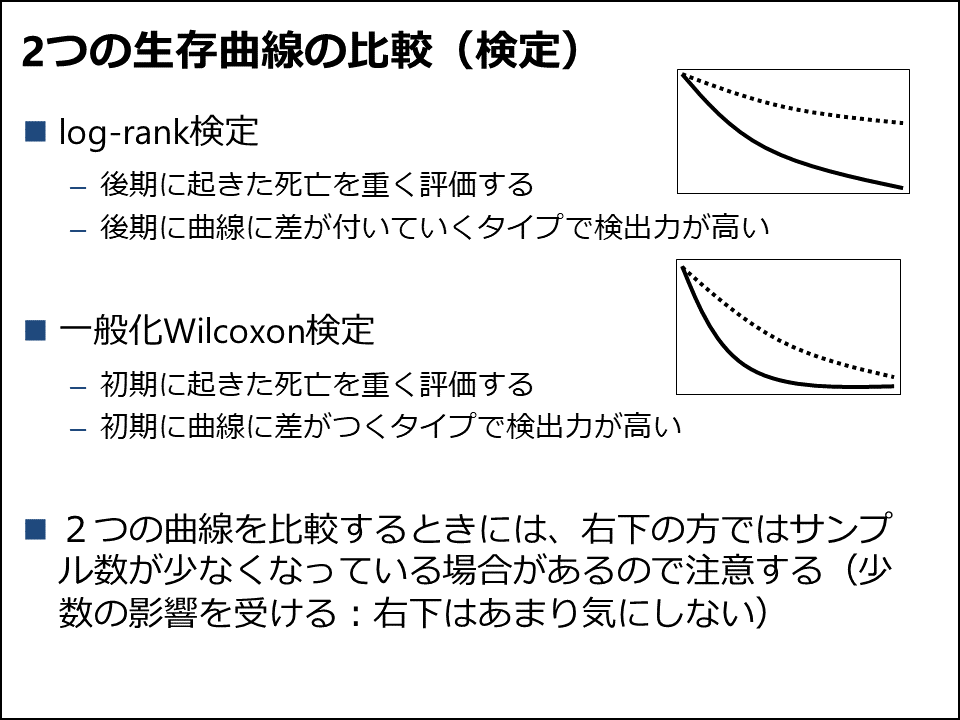
log-rank検定と一般化Wilcoxon検定
生存曲線の検定に関しては、log-rank検定と一般化Wilcoxon検定について教えています(図3)。これらの検定の原理はやや難しいので、「こういう方法がある」ということと「このように結果を見る」ということしか教えていませんし、一般的にはlog-rank検定が用いられると説明しています。これらの検定はある1時点の生存確率ではなく、曲線全体を比較しているということと、2つの曲線を比較する時には、右端の方ではサンプル数が少なくなっている場合があるので注意する(右端で少し差があったかどうかはあまり気にしない)ということは少し例を挙げてやや強調しています。
Cox回帰(比例ハザードモデル)
次はCox回帰(比例ハザードモデル)です(図4)。こちらも数理はかなり難しいので、次のスライドのように「打ち切りがある場合の特殊な回帰分析」としか教えていません。ちょうど前回の講義で多変量解析による交絡調整について扱っていますので、その生存期間バージョン(打ち切りがあるデータのバージョン)という流れで教えています。本当は比例ハザード性などもう少し詳細に教えたほうがいいのかもしれませんが、おそらく一般的な学生には「ハザード」の意味を理解するだけでも大変でしょう。「ハザードは、亡くなっていく・疾病が発症数する『スピード』である」とだけ教えています。

ここまで教えたら、実例をみて少し理解を深めてもらっています。実例はカプラン・マイヤー法による生存確率の推定、log-rank検定・一般化Wilcoxon検定、Cox回帰(多変量解析)についてです。
診断・検査の統計学
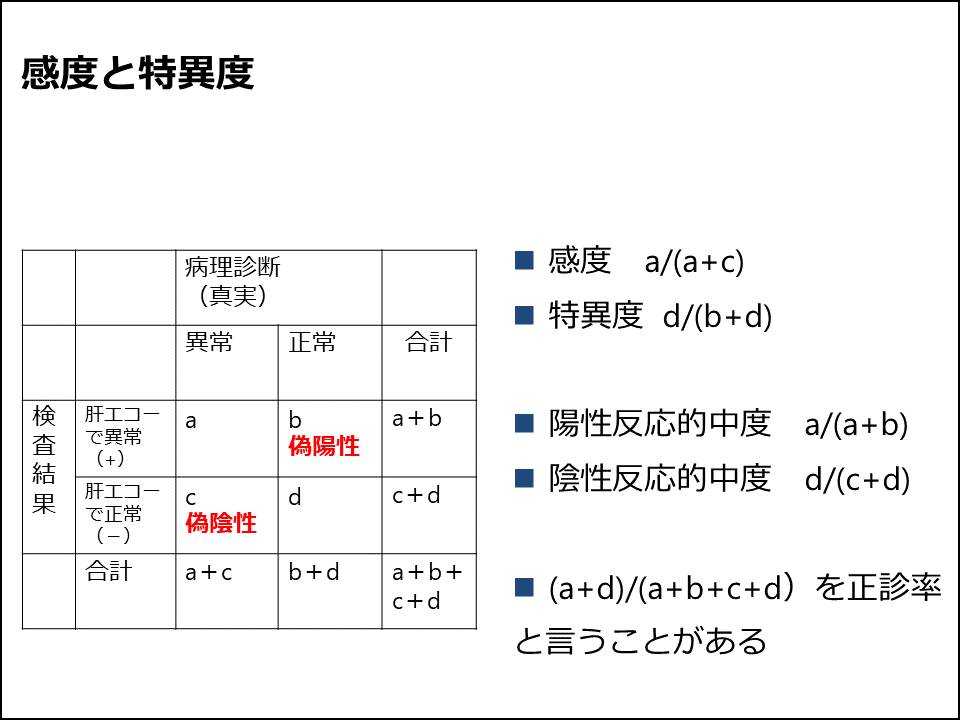
次は診断・検査の統計学です。診断・検査の統計学といってもそれらを網羅することは難しく、この講義は看護学専攻の学生と検査技術科学専攻の学生が受講していますが、検査技術科学専攻の学生は別の講義で品質管理について学んでいるようなので、この講義では検査の性能評価(感度・特異度など)についてのみ教えています(図5)。

感度と特異度
次の2枚のスライドで検査の感度・特異度について説明します(図6,7)。実際には実例を出して計算の問題も入れています。感度と特異度がトレードオフの関係にあるということも、その次のスライドのように説明します。

陽性反応的中度と陰性反応的中度
看護の学生も検査技術科学専攻の学生も、感度と特異度については既習のようですが、陽性反応的中度・陰性反応的中度については習っていないようですし、実際の検査結果を解釈するには的中度の考え方は重要かつ直観に反しているところがあるので、少し丁寧に説明しています。
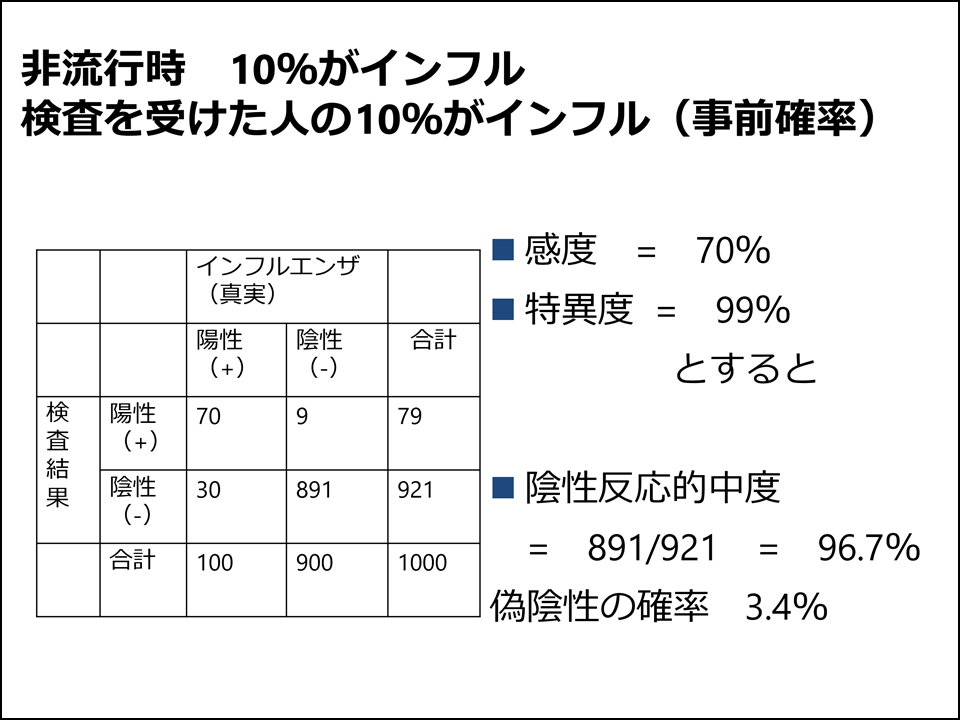
次の4枚のスライドが的中度の説明のスライドです(図8~11)。インフルエンザの診断を受けた場合、最流行期と夏場などのそうでない時期では、検査結果の解釈がまったく異なることを数値データで示しています。我ながらよい例だと思っています。もちろん、実際の判断は局所的な流行、症状、行っている病棟の特性などによって判断すべきだと教えていますが。事前確率・尤度・事後確率という言葉や周辺分布という言葉を導入するやり方もあると思いますが、私はあえてしていません。


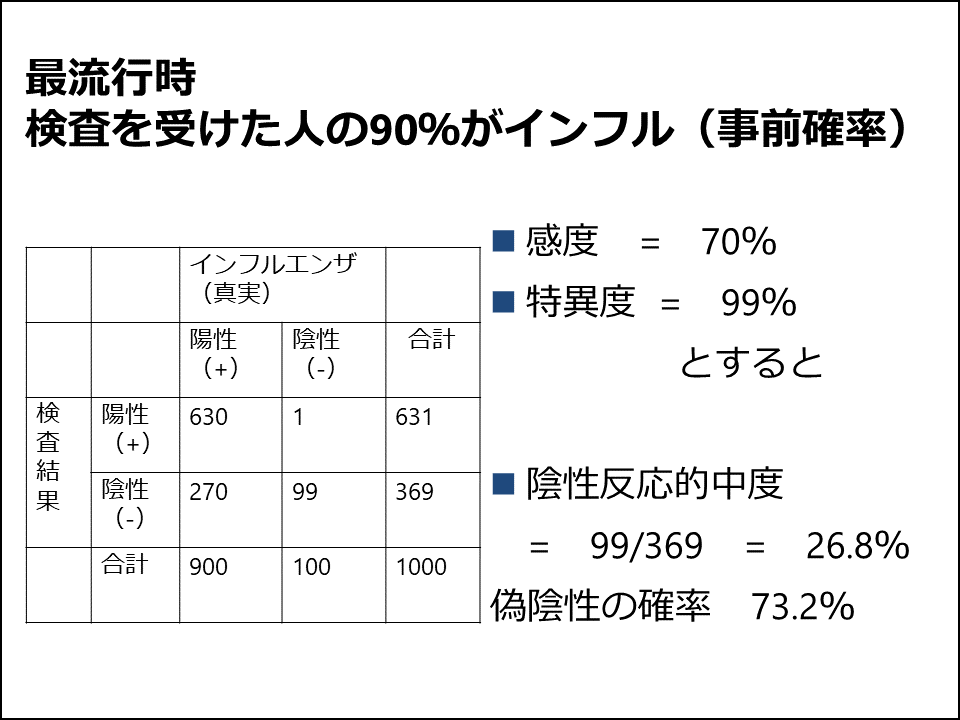
最近はCOVID-19のPCR検査の例も出しています。COVID-19は感染初期に調べた情報にわかりやすさをふまえて感度は70%、特異度は99%に設定し、PCR検査を受けた人の5%が陽性だった2020年5月頃の東京のデータと、PCR検査を受けた人の40%が陽性だった検査対象を東京の歌舞伎町などに絞っていた超初期のデータを用いています。この設定ですと5%が陽性だった2020年の5月頃では陽性反応的中度は78%、陰性反応的中度は98%になるので、PCR陽性でもそのうち22%は偽陽性ということになります。また、40%が陽性だった初期では陽性反応的中度は98%、陰性反応的中度は83%になるので、17%が偽陰性、すなわち陰性と判断されてもそれほどは安心できないことになります。最近はPCR検査の性能ももっと向上したでしょうか。それにしても、本学もまだインフルエンザで休むときには診断書を出させていますが、これって意味があるのだろうかといつも思います。もしこれらの設定どおりであれば、再流行期にインフルエンザが陰性と診断されても73%が陽性(偽陰性)なのですから。
このように検査の感度・特異度・陽性反応的中度・陰性反応的中度について説明した後には、このような診断検査を用いる場面(スクリーニングや予後予測など)について説明し、ROC曲線について説明して終了です。
症例数設計
本日の最後は症例数設計(サンプルサイズ設計)です。まずはサンプルサイズ設計を行う目的について、「統計学的検定の基本」の講義の際に統計学的有意性・臨床的有意性の講義を行ったスライドをもとに、多すぎるサンプルサイズも少なすぎるサンプルサイズも倫理的に正しくない。そのため、研究の効率だけでなく倫理的な観点からもサンプルサイズ設計が重要であることを教えています。
サンプルサイズ設計は2通りの設計方法を教えています。1つ目は標本誤差をベースとしたサンプルサイズ設計です。看護研究はアンケート調査が多いので、この方法を知っておくことは必要でしょうし、毎年卒業研究でもサンプルサイズが少なすぎるアンケート調査を目にするので、(現実的にはなかなか難しいですが)しっかりとした調査を行って欲しいという思いを込めて教えています。以下のスライドのような基本公式を教えたうえで、実際にどれくらいのサンプルサイズだと推定値の95%信頼区間がどのようになるかということを図などで示しています(図12)。

もう1つは群間比較を前提としたサンプルサイズ設計です。実際には使用する検定に依存しますが、基本的なZ検定をベースにした考え方を次のスライドのような形で教えています(図13)。このスライドは直観的にどのようなケースで必要サンプルサイズが大きく・小さくなるかというスライドです。

サンプルサイズ設計で「検出したい差」を設定するのは難しい作業です。学生には先行研究をもとに設定すると教えていますが、そのような研究を見つけてくるのは容易ではありません。サンプルサイズ設計のソフトウエアではエフェクトサイズ(効果量)をベースにしてサンプルサイズを設定するものもありますし、エフェクトサイズのよい復習になるとともに直観的にもわかりやすいこともあって、ここではエフェクトサイズの説明をもう一度しながら、これらをベースに設定することもできることを示しています。最後は本学で無料で使用できるJMPのサンプルサイズ設計機能を使ってサンプルサイズ設計をいくつか例示して終わりです(図14,15)。


ここまでで医療統計学はだいたい終わりました。次回は評価尺度の作り方と信頼性・妥当性の検証について説明して、医療統計学のパートを終了します。

_1695266438714.png)


